This section consists of three parts and the first two are presenting one common programming issue. The issue in few steps: reading a csv file, grouping the data of csv by IDs, measuring means on the groups based on its number data (float), return a table of the results (ID, number, mean). The table of the results will be saved into files, so we get a pdf file in the case of the first solution, and in the second we get an xlsx file. In the first part of this section you can see a solution with creating database (Sql). Instead of database in the second part I have used concepts based on functions from the Pandas library. For this problem the second one is more optional solution, therefore with the first example I tried rather to bring into focus the basics of queries from library sqlite3. The third part of this section is about list comprehensions, some lambda and map functions to convert data types of arrays, dictionaries.
Info! The explanations of the code you can see below are written in Hungarian language, but I pushed the codes to gitHub as well and attached readme file to sqlite example with brief description in English. Here is the link: github.com/sqlite_example
A most következő program egyrészt a Python egy adatbázis kezelő moduljára hoz szemléletes példát (sqlite3), másrészt a pdf szerkesztést (reportlab), mint a program egy lehetséges kimeti módját mutatja be alapjaiban. A program egy neveket (a fájlban: kódok) és lebegőpontos számértékeket tartalmazó csv fájl beolvasásával kezdi, létrehoz egy adatbázist, majd benne egy táblát és a fájlból beolvasott tartalmat ebbe a táblába tölti fel. Ezután a megegyező nevekhez tartozó számok átlagát kérdezi le és egy kimeneti csv fájlba másolja. A program másik kimeneteként az adatbázis lekérdezés eredménye egy fájlba szerkesztett táblázatba is bekerül, pdf formátumban.
import sqlite3
import csv
from reportlab.pdfgen import canvas
from reportlab.lib.pagesizes import A4, landscape
from reportlab.pdfbase import pdfmetrics
from reportlab.pdfbase.ttfonts import TTFont
from reportlab.platypus import Table, TableStyle, Image
from reportlab.lib import colors
# FÜGGVÉNYEK / FUNCTIONS
def csvin(fname):
" Beolvassa a csv fájl adatait egy tömbbe -> list:*tuple "
" read csv data into array "
with open(fname, 'r') as f:
reader = csv.reader(f, delimiter=';')
next(reader) # ignore 0.row!
data = [tuple(i) for i in reader]
return data
def csvout(out_csv, data, col):
" SQL query-t beolvassa egy csv fájlba "
" read data from SQL query into csv "
with open(out_csv, 'w', newline='') as f:
writer = csv.writer(f, delimiter=';')
for i in data:
writer.writerow(i)
return out_csv
Fentebb a program által használt két függvény látható. Az első (csvin) egy csv fájl vesszővel (itt pontosvessző a karakterkódolásnak megfelelően) elválasztott adatait (egyébként: csv=comma separated values) olvassa be egy speciális Python tömbbe ún. tuple-ba. A második (csvout) éppen fordítva jár el és az adattáblából származó adatokat olvassa be egy csv fájlba. Az alábbi kódrészlet az adatbázis létrehozását, a csv fájl előkészítését – a már említett módon -, az adattábla létrehozását, feltöltését, az átlagok kiszámítását – a nevek alapján – tartalmazza. Ezeket az átlagokat egy sql lekérdezés (SELECT >> COUNT >> AVG) segítségével számítjuk ki, majd egy csv fájlba másoljuk a csvout felhasználásával.
# ADATBÁZIS létrehozás és csatlakozás / create DB & connect
db_name = "c:\\temp\\test_results.db"
conn = sqlite3.connect(db_name)
c = conn.cursor()
# Teszt - létezik-e a tábla? / if table is exist?
try:
c.execute("SELECT * FROM value_table")
except:
pass
else:
c.execute("DROP TABLE value_table")
# FÁJL tartalmának beolvasása tömbbe / read content to array
fname = "c:\\temp\\results.csv"
file_cont = csvin(fname)
# ADATTÁBLA létrehoz / create data table
create_res = " CREATE TABLE IF NOT EXISTS value_table (Id INTEGER PRIMARY KEY NOT NULL, kód TEXT, érték REAL); "
c.execute(create_res)
# ADATTÁBLA feltölt / insert into data table
insert_res = " INSERT INTO value_table (Id,kód,érték) VALUES (?,?,?); "
c.executemany(insert_res, file_cont)
# ÁTLAGOK kiszámol / count mean
result_atlag = " SELECT kód, COUNT(*) as kód, round(AVG(érték),2) as result_avg FROM value_table GROUP BY kód "
c.execute(result_atlag)
# A SELECT lekérdezés tömbbe másolása / selection into array
avgs = c.fetchall()
avgs.insert(0,("Id","kód","érték")) # +fejléc / +header
# OUTPUT -> csv -> pdf
# Eredmények csv fájlba / results into csv
newFile = "c:\\temp\\avg.csv"
csvout(newFile,avgs,3)
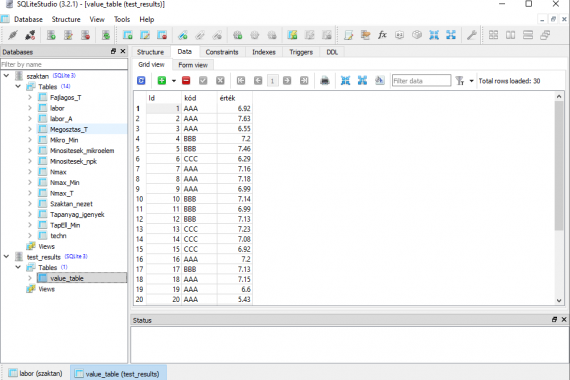
A fenti képen az adatbázisban létrehozott adattábla (value_table) és az adatok (kód;érték) láthatók, mely az SQLitesStudio adatbázis kezelő programmal nyitható meg. Az alábbi kódrészletben pedig a lekérdezésből származó adatok, vagyis az átlagértékek pdf fájlba való kiíratásának (táblázatos formában) és mentésének kódja látható.
# Eredmények pdf fájlba / results into pdf
width, height = A4
pdfmetrics.registerFont(TTFont('Times', 'Times.ttf'))
pdf_name = "c:\\temp\\avg.pdf"
c = canvas.Canvas(pdf_name) # fájl neve / file name
c.setFont('Times', 16)
title_names = "Átlagok:"
c.drawCentredString(150,height-50,title_names)
c.setFont('Times', 12)
table = Table(avgs, 100, 25)
table.setStyle(TableStyle([
('ALIGN', (0,0), (-1,-1), 'CENTER'),
('VALIGN',(0,0),(-1,-1),'MIDDLE'),
('FONTNAME', (0,0),(-1,-1), 'Times'),
('BACKGROUND',(0,0),(-1,-1), colors.whitesmoke),
('BACKGROUND',(0,0),(2,0), colors.lightskyblue),
]))
table.wrapOn(c, width,height)
table.drawOn(c, 100,height-180)
c.save()
# ADATBÁZIS bezárása / close DB
conn.commit()
conn.close()
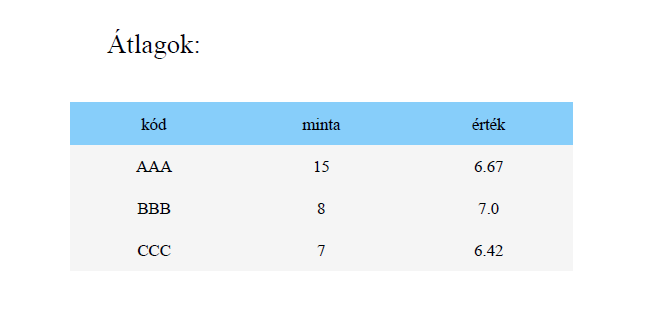
A képeken az átlagszámítás alapjául szolgáló csv fájl tartalma és a pdf fájlból kivágott, minimálisan formázott táblázat látható.

Az előző feladat megoldása Pandas használatával
Az előző példa célja az Sql és Python együttműködésének bemutatása volt, miközben maga a programozási feladat megoldható jóval egyszerűbben, adatbázis létrehozása nélkül is. Ilyen lehetőség Pythonban például a Pandas könyvtár osztályainak és függvényeinek a meghívásával nyílik. A feladat tehát itt is ugyanaz: azonos Id-jű elemekhez tartozó lebegőpontos (float) értékekből számított átlagok, majd visszatérés az eredményekkel egy összefoglaló táblázatba. Az alábbi megoldás még annyiban is eltér az előzőtől, hogy az eredmény táblázatot nem pdf-ben, hanem Excel formátumban mentettem el, meghívva a Pandas to_excel() függvényét.
import pandas as pd
class Demo():
def __init__(self, table):
" Input adatok <- csv táblák / input data <- csv tables "
self.tab = self.__readCsv(table)
self.count = []
self.tab_A = self.__groupBy(self.tab,'kód')
self.resInDataframe().to_excel("c:\\temp\\pd_portfolio\\avg.xlsx",sheet_name='Atlagok')
def __readCsv(self, csvfile):
" csv fájlt beolvas / read csv file... "
return pd.read_csv(csvfile, sep=';', decimal=',', encoding="iso-8859-2")
def __groupBy(self, df,by):
" Kiválasztott számok átlaga 'groupby' id alapján / counting means by Ids "
self.count =list(df.groupby(by).size().values)
df = df.groupby(by, as_index=False, sort=False).mean()
return df.round(2)
def resInDataframe(self):
""" 1. Eredmények dictionary-be foglalása / res to dict
2. Visszatértés pandas DataFrame-ben / ret to DataFrame """
d = {'kód': self.tab_A['kód'], 'minta': self.count, 'érték': self.tab_A['érték']}
df = pd.DataFrame(data=d)
return df
def main(self):
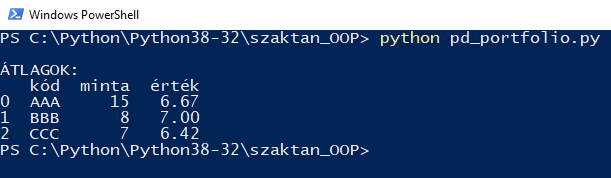
print('\nÁTLAGOK: ')
print(self.resInDataframe())
if __name__ == "__main__":
tabla = "c:\\temp\\pd_portfolio\\results.csv"
c = Demo(tabla)
c.main()
A Demo osztály az __init__ konstruktoron és a main() metóduson kívül három metódust tartalmaz. A konstruktorban történik az Id-ket és a hozzájuk tartozó törtszámokat tartalmazó adatfájl beolvasása, a csoportok nagyságát tartalmazó lista (amely azt az információt tartalmazza, hogy hány értékből számoltuk ki az Id-khez rendelt átlagértékeket), végül pedig a feladat célját képező csoportosító és az xlsx fájlba mentést végző Pandas függvények. A main() metódus célja, hogy kiírassa a konzolra az eredményeket, a resInDataframe() metódus meghívásával, amely egy Pandas Dataframe-be foglalja az azonosító kódot, az aggregálás nagyságát (minta) illetve magát a számított átlagértéket (érték).
A konstruktorban meghívott két másik metódus, a __readCsv() illetve a __groupBy() rendre az adatfájl beolvasását és a csoportosítását végzi a ‘kód’ címke/kulcs alapján. Az átlagszámításhoz az adatcsoportra hívjuk meg a mean() függvényt, ahogy az a kódban is látható. Az input adatok beolvasása, amely az előző példához hasonlóan itt is egy csv fájlból történik, a Magyarországon is érvényes vesszős törtalakot használja (ebben is eltér az előző feladathoz képest, mivel ott az angolszász típusú pontos elválasztás érvényes). A __groubBy() metódusban először is listába gyűjtjük, hogy hány értékből kaptuk meg az adott Id-re vonatkozó átlagot (self.count: csoportosítás->méret->értékek), majd elvégezzük az azonosítók csoportosításával az átlagszámítást anélkül, hogy a kulcsot indexként jelölnénk ki (as_index=False) illetve anélkül, hogy az eredményeket sorrendben kérnénk vissza (sort=False). Ez utóbbi argumentummal megtartottuk a feldolgozás sorrendjét!
Tömb elemek átalakítása
Gyakran felmerülő probléma a karakterláncok módosítása és a tömbök adattípusának átalakítása, hiszen a kimenetként kapott tömb nem mindig megfelelő típusú, formátumú. Ez gond lehet mind a számításoknál, mind pedig az adatok ábrázolásánál. A következőkben típusok változtatására illetve modosítására mutatok példákat, melyekhez a Python list comprehension-t, a lambda és map függvényeket használtam fel.
# list of integers my_ints = [ 2, 3, 5, 6, 11, 3, 5, 1 ] # with list comprehension my_flts = [ float(i) for i in my_ints ] # without loop, with map & lambda my_mp = map(lambda x: float(x), my_ints) # results print(list(my_mp)) >> [2.0, 3.0, 5.0, 6.0, 11.0, 3.0, 5.0, 1.0]
# list of strings my_str = [ '2.12', '1.1', '3.14', '2.0', '4.566' ] # with list comprehension my_flts2 = [ float(i) for i in my_str ] # without loop, with map & lambda my_mp2 = map(lambda x: float(x), my_str) # results print(list(my_mp2)) >> [2.12, 1.1, 3.14, 2.0, 4.566]
# list of comma separated strings
strs = [ '217,139', '171,149', '187,210', '116,232', '182,575' ]
# with list comprehension
strs_to_float_li = [ float(i.replace(',','.')) for i in strs ]
# without loop, with map & lambda
strs_to_float_mp = map(lambda x: float(x.replace(',','.')), strs)
# results
print(list(strs_to_float_mp))
>> [217.139, 171.149, 187.21, 116.232, 182.575]
# list with condition, sorting 1st and 0 values coords = [102.79, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 3.82, 21.31, 61.21, 13.27, 0.4, 0.0, 0.0, 0.0] # with list comprehension coords_li = [i for i in coords[1:] if i > 0] # without loop, with filter & lambda coords_fi = filter(lambda x: x > 0, coords[1:]) # results print(list(sorted(coords_fi))) >> [0.4, 3.82, 13.27, 21.31, 61.21]
# numbers of list of tuples - RGBs colors = [(255, 255, 255), (75, 0, 130), (0, 109, 176), (138, 43, 226), (65, 105, 225), (72, 61, 139)] # with 2 'for loops' colors_li = [ tuple([i/255 for i in rgb]) for rgb in colors ] # with 1 'for loop' colors_mp = [ list(map(lambda x: x/255, rgb)) for rgb in colors ] # results print(colors_mp) >> [(1.0, 1.0, 1.0), (0.29411764705882354, 0.0, 0.5098039215686274), (0.0, 0.42745098039215684, 0.6901960784313725), (0.5411764705882353, 0.16862745098039217, 0.8862745098039215), (0.2549019607843137, 0.4117647058823529, 0.8823529411764706), (0.2823529411764706, 0.23921568627450981, 0.5450980392156862)]
coords = { 'coords': '12,45', 'test': '5,67' }
# solution 1.
res = [] # list
for k,v in coords.items():
elem = float(v.replace(',','.'))
res.append(elem) # add to list
res = tuple(res)
print(res)
# solution 2.
res2 = map(lambda v: float(v.replace(',','.')), coords.values())
# results
print(tuple(res2))
>> (12.45, 5.67)
# long dict
coords = { 'coords': [ '132,34', '147,87', '206,86', '217,139', '171,149', '187,210', '116,232', '182,575', '436,497', '281,79' ] }
# get 'coords' key values and split them to tuples
split_coords_to_int = [ tuple(map(int, i.split(','))) for i in coords['coords'] ]
# results
print(split_coords_to_int)
>> [(132, 34), (147, 87), (206, 86), (217, 139), (171, 149), (187, 210), (116, 232), (182, 575), (436, 497), (281, 79)]